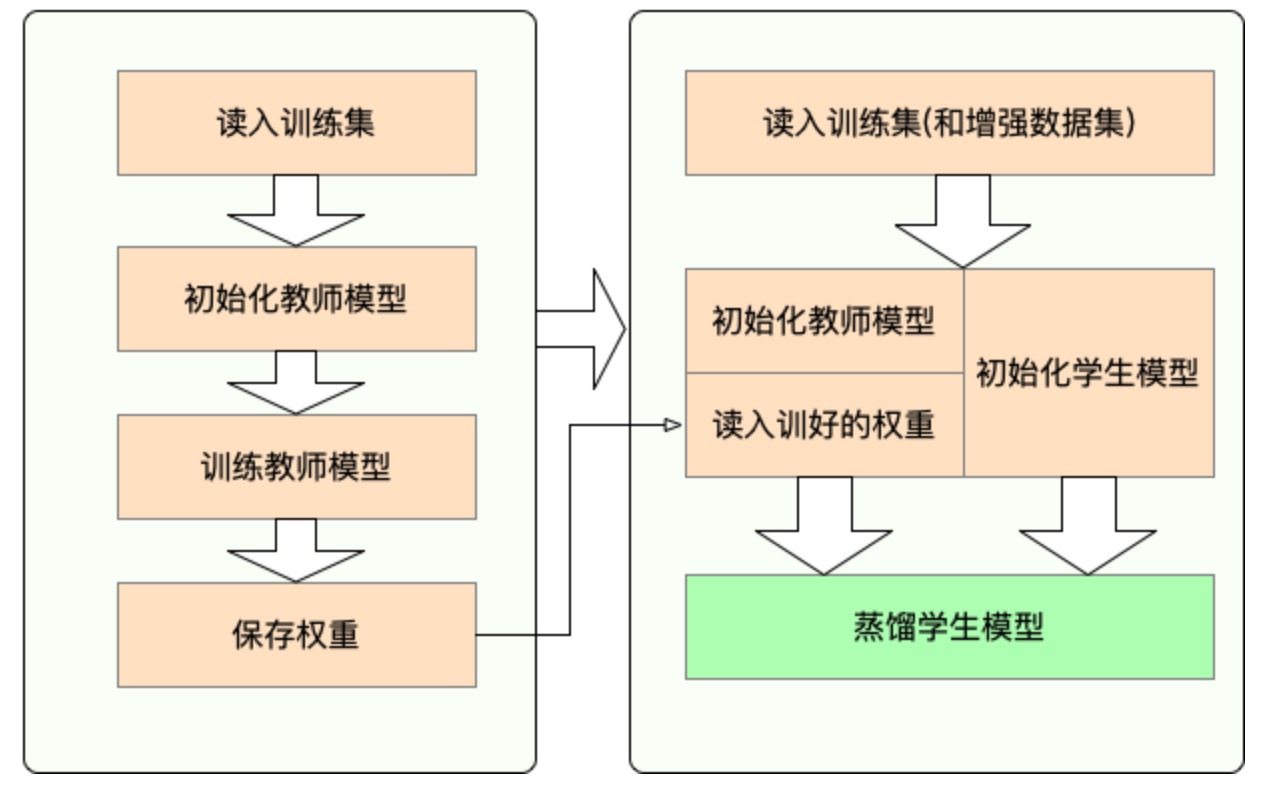
模型压缩
一.压缩的技巧
1.1 模型剪枝(Network Pruning)
- 方法:将网络中的权重或者神经元进行删除,再次重新训练。
- 原因:大的网络中包含很多冗余参数,而小的网络很难训练,那就直接用大的网络删减成小网络就好了。
- 应用:属于神经网络就可以。
1.2 结构设计(Architecture Design)
- 方法:通过设计更少参数的layer来替代现有layer(效果不变情况下)
- 原因:模型中有些layer可能参数很冗余,例如DNN。
- 应用:利用套用新的模型结构或者新的layer。
1.3 参数量化(Parameter Quantization)
- 方法:将网络中常用的计算单位(float32/float64)压缩成更小的单位(比如int8)
- 原因:计算的单位变得更小,运算更快。
- 应用:对所有已经训练好的model使用;或者边训练边诱导model去量化。
1.4 知识蒸馏(Knowledge Distillation)
- 方法:利用一个已经学好的大model,来教小model如何做好任务。
- 原因:让学生直接做对题目太难,可以偷看老师是怎么做题的。
- 应用:通常用于classification(也可以用于generative model生成式模型比如GAN),而且学生只能从头学起。
1.5 混合使用的例子
这里其实在我面试的时候考过一次,当时只考虑了模型选型用mobilenet和参数量化,没有考虑到知识蒸馏和模型剪枝
比如我现在需要一个极小的model来学习图像分类任务。这里完全可以使用以上技巧来混合压缩模型,如下图所示
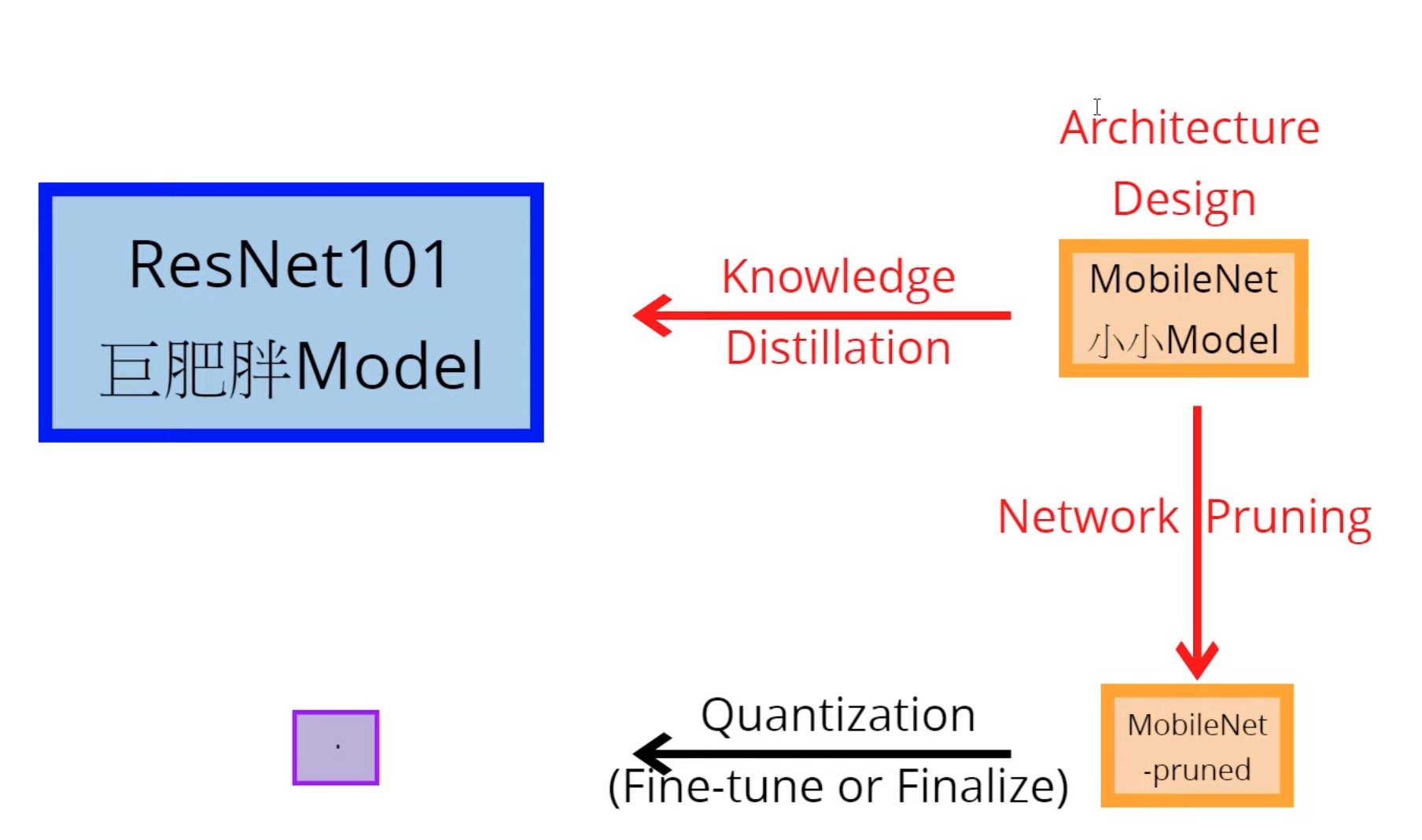
- 可以先选择小的cv模型架构(这里选择mobilenet)来对大的图像分类模型(比如resnet101这种大且深的model)进行知识蒸馏。
- 然后将蒸馏后的mobilenet进行模型剪枝,进一步减少模型中冗余参数。
- 其次,利用参数量化将模型的计算单位压缩成int8,从而得到最终压缩后的模型。
二. 知识蒸馏
知识蒸馏最主要的问题其实是:蒸馏哪里?
-
输出(Logits):
-
- 直接匹配logits
- 让student学习teacher的logits distribution(在一个batch里面)
-
中间值(Feature):
-
- 直接匹配中间的feature
- student学习teacher的Feature是如何转换的
2.1 输出蒸馏
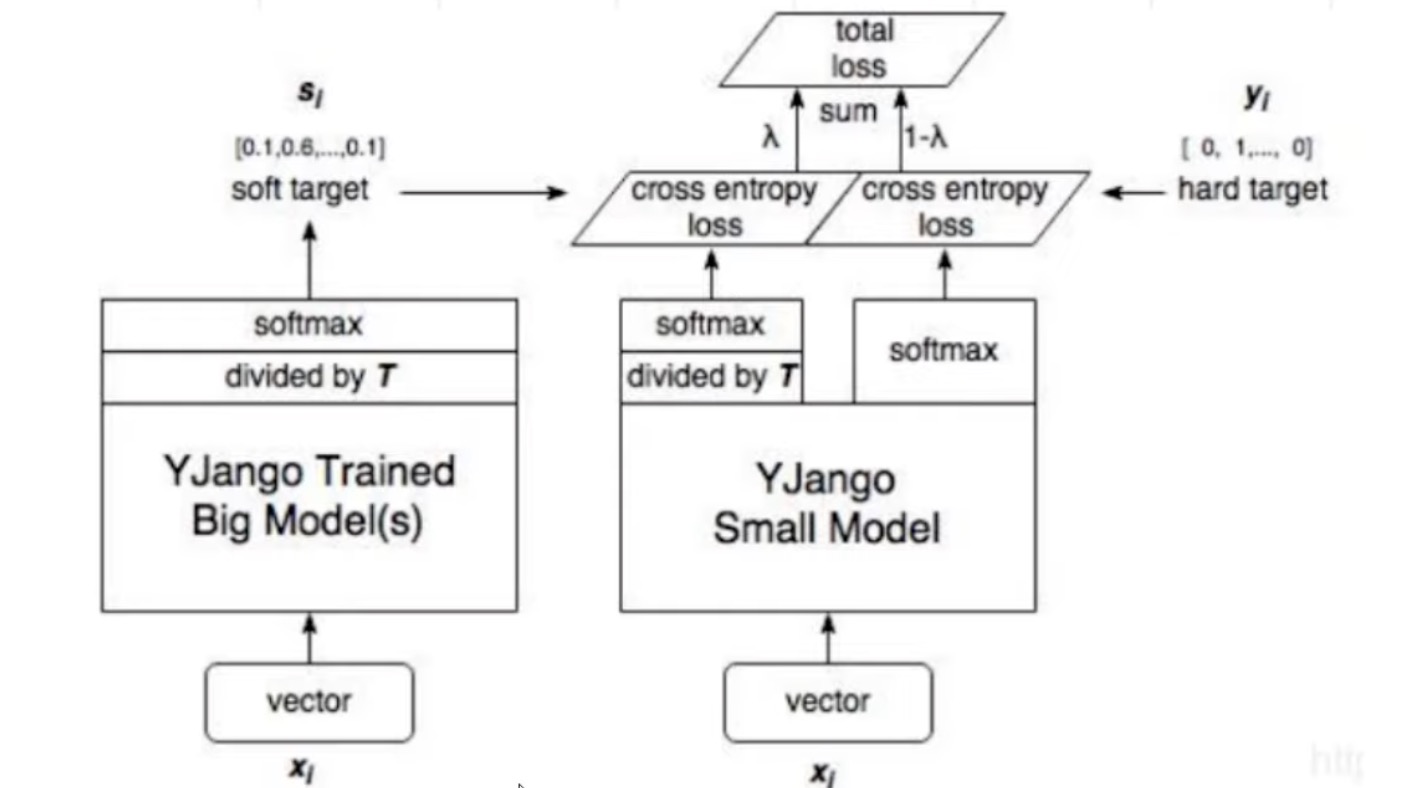
Distilling the Knowledge in a Neural Network
- 论文地址:https://arxiv.org/pdf/1503.02531.pdf
- 核心方法:让大的model的logits除掉T(原因是由于大model其实已经学很好,导致logits都是1,除掉T之后变得不要那么完美)之后得到soft target,然后让小model去学习hard target和soft target结合起来的loss。
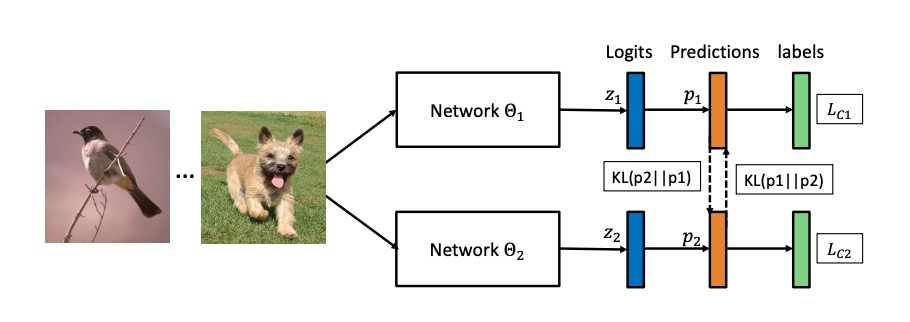
Deep Mutual Learning
- 论文地址:https://arxiv.org/pdf/1706.00384.pdf
- 核心方法:让两个network同时学习,互相学习对方的logits,同时让其看到真实的label的样子。
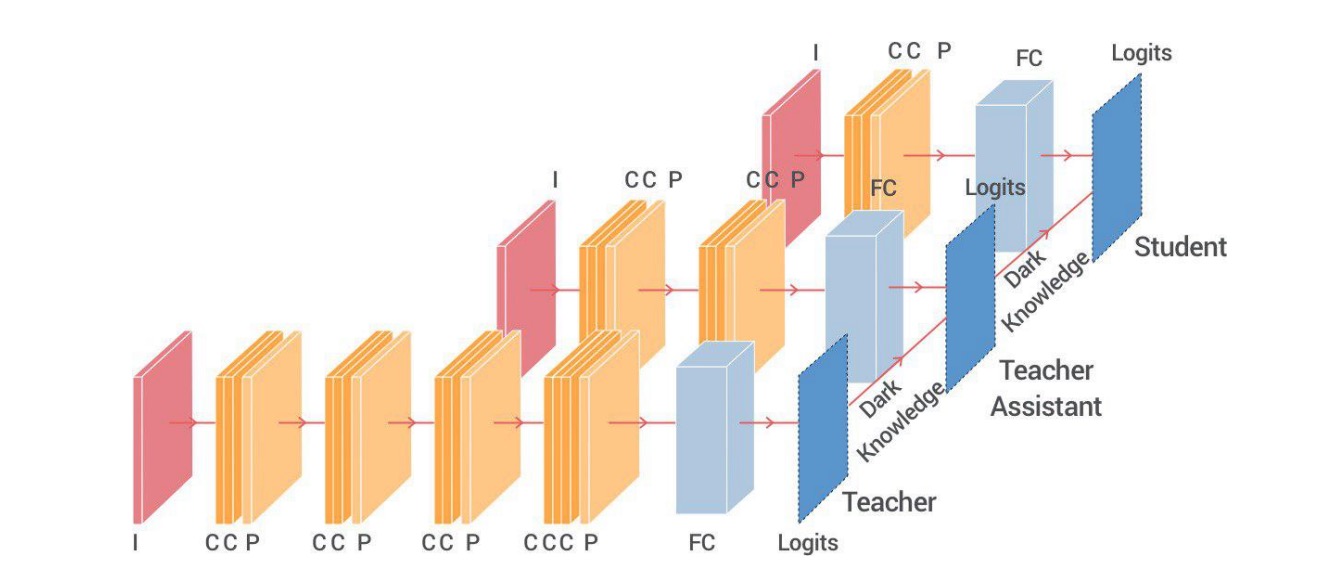
Improved Knowledge Distillation via Teacher Assistant
- 论文地址:https://arxiv.org/pdf/1902.03393.pdf
- 核心方法:当小的model无法理解/学习大型model的时候,这里引出“Teacher Assistant”(助教)来作为中间model,起到学习大model,来教小model。
2.2 中间值蒸馏
FITNETS: HINTS FOR THIN DEEP NETS
- 论文地址:https://arxiv.org/pdf/1412.6550.pdf
- 核心方法:当小的model无法理解/学习大型model的时候,这里引出“Teacher Assistant”(助教)来作为中间model,起到学习大model,来教小model。
2.3 知识蒸馏开源代码推荐
github 地址:https://github.com/airaria/TextBrewer
这个repo是哈工大开源的知识蒸馏的工具包(基于pytorch、bert的工具包,偏向于文本)。下面是具体的使用的流程