文本标注工具Brat
一. brat的介绍
在文本领域,特别是需要对实体、关系进行标注的情况下,我们是十分需要一个开源便捷的打标工具帮助我们生成属于自己的数据集的。所以之前一直在想,文本里有没有像图像里标注labelme一样的开源打标工具呢?还真有,而且还不少。这里推荐一个本人用的很顺手的文本标注工具——brat。
brat工具的特点:
- 使用方便,可直接应用于webserver端。
- 开源
- 支持实体、关系、事件的标注。
- python写的,因此方便改写脚本(支持python2和python3)
- 支持中文展示
- 支持Linux、Mac系统
二. brat的安装及使用
1.2 安装
github仓库地址:https://github.com/nlplab/brat
安装步骤:
- 直接clone仓库到本地
- 进入主目录下,并本地web服务:
cd brat & python standalone.py - 在看到
Serving brat at http://0.0.0.0:8001后,在网页中输入http://0.0.0.0:8001即可看到本地brat服务了。 - 注意这里需要注册和登录账号
以上全部流程走完后,你就可以真正开始使用brat了。
2.2 使用
brat的使用也是特别简单,大家可以跟着我的流程一步一步走:
- 在brat的主目录下有一个
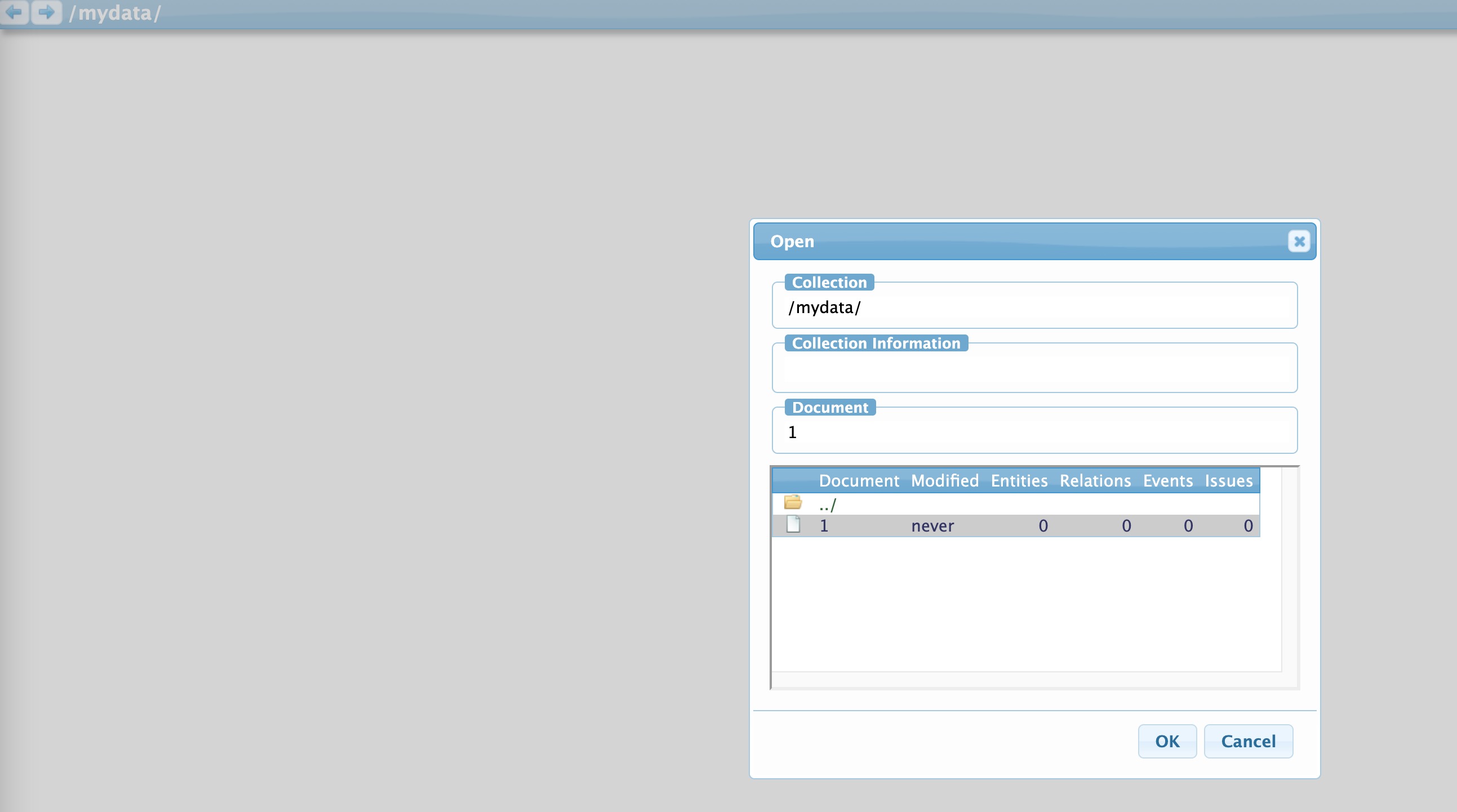
data目录,其中是存放的我们需要打标的数据。 - 在data目录下
cd data新建一个属于我们自己的数据集目录:mkdir mydata - 在
mydata目录下新建一个需要打标的txt文件并随便写点啥:vim 1.txt - 新建专属于自己的标注类别conf文件:
vim annotation.conf
[entities]
person
act
like
hate
[relations]
Act-Person Arg1:<ENTITY>, Arg2:<ENTITY>
[events]
[attributes]
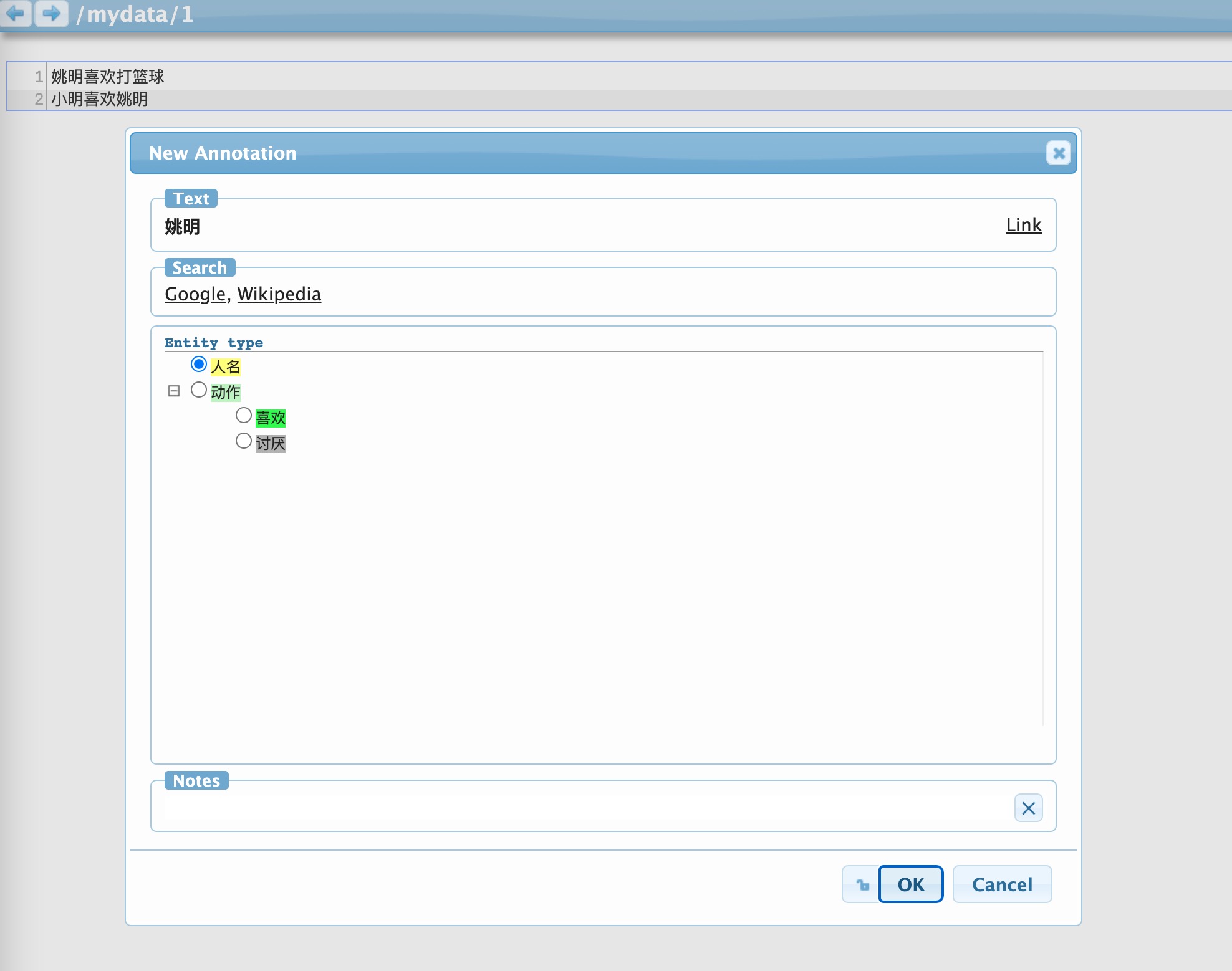
这里我只需要对实体和关系进行标注,比如我需要标注实体:人物,动作(包含喜欢/讨厌);关系:人物和动作的关系
当我们在网页server端打开/mydata/1.txt后,可以如下图开始标注了
- 定制化实体/关系颜色及中文展示,在
mydata目录下新建一个conf文件:vim visual.conf
[labels]
person | 人名
like | 喜欢
hate | 讨厌
[drawing]
SPAN_DEFAULT fgColor:black, bgColor:lightgreen, borderColor:darken
ARC_DEFAULT color:black, arrowHead:triangle-5
person bgColor:yellow, borderColor:red
like bgColor:green, borderColor:red
hate bgColor:gray, borderColor:red
接下来,就会在标注的页面看到如下所示了。
三. brat结果输出及扩展(干货)
3.1 实体BIO输出
当我们标注完成之后,需要将实体的标注结果转成BIO进行输出,这该怎么输出呢?
- 其实可以直接使用brat的python脚本直接将标注的.ann文件输出成BIO形式的.conll文件
- 在brat的主目录下进入
tools目录,利用python输出结果:python anntoconll.py ../data/mydata/1.txt - 这里就可以在
mydata目录下看到1.conll文件了,如下所示
B-person 0 1 姚
I-person 1 2 明
B-like 2 3 喜
I-like 3 4 欢
O 4 5 打
O 5 6 篮
O 6 7 球
B-person 8 9 小
I-person 9 10 明
B-like 10 11 喜
I-like 11 12 欢
B-person 12 13 姚
I-person 13 14 明
3.2 实体BIO输出脚本错误检查
当我们利用brat自带的python脚本anntoconll.py脚本生成来conll文件后,其实会有bug存在(亲测),啥bug呢?
比如“小明小李”这两个实体连在了一起,你的ann命名显示着“小明”和“小李”分别是一个PERSON,但是经过anntoconll.py脚本生成后的conll文件后,你会发现只有一个实体“小明小李”,因此我们还需要一个检查脚本来修改这个bug。
import os
import sys
def read_file(file_path):
with open(file_path, 'r',encoding='utf8') as file:
lines = file.readlines()
return lines
def write_file(file_path, lines):
with open(file_path, 'w',encoding='utf8') as file:
for line in lines:
file.write(line)
def check_one_file(conll_path, ann_path):
# check process: 针对conll文件进行检查B开头的字符是否通过brat转化后是正确的
ann_lines = read_file(ann_path)
conll_lines = read_file(conll_path)
begin_words, begin_index = [], []
for ann_i in ann_lines:
class_i, start_i, end_i = ann_i.split('\t')[1].split(' ')
begin_words.append('B-' + class_i)
begin_index.append(start_i)
ann_zip = dict(zip(begin_index, begin_words))
# check
new_conll = []
for conll_i in conll_lines:
if conll_i == '\n':
new_conll.append(conll_i)
else:
tag_i, start_i, end_i, word_i = conll_i.split('\t')
if start_i in begin_index:
if tag_i != ann_zip[start_i]:
new_conll.append(ann_zip[start_i] + '\t' + start_i + '\t' + end_i + '\t' + word_i)
else:
new_conll.append(conll_i)
else:
new_conll.append(conll_i)
return new_conll
if __name__ == '__main__':
sub_dir = sys.argv[1]
# sub_dir = '../data/fd'
# 生成一个保存新conll文件的文件夹
new_dir = os.path.join(sub_dir,'conll')
if not os.path.exists(new_dir):
os.mkdir(new_dir)
path_pre = []
for path_i in os.listdir(sub_dir):
if path_i.endswith('.ann'):
path_pre.append(path_i.split('.ann')[0])
for path_pre_i in path_pre:
ann_path_i = os.path.join(sub_dir,f'{path_pre_i}.ann')
conll_path_i = os.path.join(sub_dir,f'{path_pre_i}.conll')
new_conll_i = check_one_file(conll_path_i,ann_path_i)
new_path_i = os.path.join(new_dir,f'{path_pre_i}.conll')
write_file(new_path_i,new_conll_i)
print(f'Write {conll_path_i} completed!')
3.3 实体BIOE输出
当我们标注完成之后,需要将实体的标注结果转成BIOE格式进行输出,这该怎么输出呢?
def bioe_transfer(tags:List[List[str]]):
"""
将BIO格式转成BIOE格式
"""
new_tags_all = []
for tags_i in tags:
new_tags = []
for i in range(len(tags_i) - 1):
tag_i = tags_i[i]
tag_after = tags_i[i + 1]
if tag_i == 'O':
new_tags.append(tag_i)
else:
if tag_i.split('-')[0] == 'B':
new_tags.append(tag_i)
else:
if tag_i == tag_after:
new_tags.append(tag_i)
else:
# 最后一个
new_tags.append('E-' + tag_i.split('-')[1])
if tags_i[-1] == tags_i[-2]:
if tags_i[-1] == 'O':
new_tags.append('O')
else:
new_tags.append('E-' + tags_i[-1].split('-')[1])
else:
new_tags.append(tags_i[-1])
new_tags_all.append(new_tags)
return new_tags_all
3.4 关系结果输出(干货)
关系结果输出我实在是找不到啥脚本了,因此干脆自己写吧,下面是我自己写的脚本(随便写的,勿喷!)
import pandas as pd
import numpy as np
import sys
if __name__ == '__main__':
path_txt = sys.argv[1]
line_start = []
line_end = []
line_len = []
with open(path_txt,'r',encoding='utf8') as txt_f:
txt_lines = txt_f.readlines()
num = 0
for txt_i in txt_lines:
txt_i = txt_i.split('\n')[0]
line_len.append(len(txt_i))
if num == 0:
start_i = num
else:
start_i = num + 1
line_start.append(start_i)
num = start_i + len(txt_i)
line_end.append(num)
rel_label = []
rel_index_1 = []
rel_index_2 = []
ent_index = []
ent_label = []
ent_start = []
ent_end = []
ent_words = []
with open(path_txt.split('.txt')[0] + '.ann','r',encoding='utf8') as ann_f:
ann_lines = ann_f.readlines()
for ann_i in ann_lines:
e_r_i = ann_i.split('\t')[0]
if 'R' in e_r_i:
rel_i = ann_i.split('\t')[1].split(' ')
rel_label.append(rel_i[0])
rel_index_1.append(rel_i[1].split(':')[1])
rel_index_2.append(rel_i[2].split(':')[1])
else:
rs_ent = ann_i.split('\t')
ent_index.append(rs_ent[0])
ent_words.append(rs_ent[2].strip())
rs_ent_in = rs_ent[1].split(' ')
ent_label.append(rs_ent_in[0])
ent_start.append(int(rs_ent_in[1]))
ent_end.append(int(rs_ent_in[2]) - 1)
df_ent = pd.DataFrame({'index':ent_index,'words':ent_words,'label':ent_label,'start':ent_start,'end':ent_end})
df_rel = pd.DataFrame({'label':rel_label,'ent_1':rel_index_1,'ent_2':rel_index_2})
df_line = pd.DataFrame({'txt':txt_lines,'start':line_start,'end':line_end})
ent_1_label = []
ent_1_words = []
ent_1_start = []
ent_1_end = []
ent_2_label = []
ent_2_words = []
ent_2_start = []
ent_2_end = []
txt_rep = []
txt_rep_start = []
for i in range(len(df_rel)):
ent_1_i = df_rel.loc[i,'ent_1']
ent_2_i = df_rel.loc[i,'ent_2']
ent_1_label.append(np.array(df_ent.loc[df_ent['index'] == ent_1_i,'label'])[0])
ent_1_words.append(np.array(df_ent.loc[df_ent['index'] == ent_1_i,'words'])[0])
ent_1_start.append(np.array(df_ent.loc[df_ent['index'] == ent_1_i,'start'])[0])
ent_1_end.append(np.array(df_ent.loc[df_ent['index'] == ent_1_i,'end'])[0])
ent_2_label.append(np.array(df_ent.loc[df_ent['index'] == ent_2_i, 'label'])[0])
ent_2_words.append(np.array(df_ent.loc[df_ent['index'] == ent_2_i, 'words'])[0])
ent_2_start.append(np.array(df_ent.loc[df_ent['index'] == ent_2_i, 'start'])[0])
ent_2_end.append(np.array(df_ent.loc[df_ent['index'] == ent_2_i, 'end'])[0])
# 匹配文档
ent_1_index = np.array(df_ent.loc[df_ent['index'] == ent_1_i, 'start'])[0]
df_line_i = df_line[(df_line['start'] <= ent_1_index) & (df_line['end'] >= ent_1_index)]
txt_rep_i = np.array(df_line_i['txt'])[0]
txt_rep_start_i = np.array(df_line_i['start'])[0]
txt_rep.append(txt_rep_i)
txt_rep_start.append(txt_rep_start_i)
df_rel['ent_1_label'] = ent_1_label
df_rel['ent_1_words'] = ent_1_words
df_rel['ent_1_start'] = ent_1_start
df_rel['ent_1_end'] = ent_1_end
df_rel['ent_2_label'] = ent_2_label
df_rel['ent_2_words'] = ent_2_words
df_rel['ent_2_start'] = ent_2_start
df_rel['ent_2_end'] = ent_2_end
df_rel['txt'] = txt_rep
df_rel['txt_start'] = txt_rep_start
df_rel.drop(['ent_1','ent_2'],axis=1,inplace=True)
csv_path = path_txt.split('.txt')[0] + '.csv'
df_rel.to_csv(csv_path, index=False)
print(f'Saved in {csv_path}!')
3.5 模型预测结果展示为brat(干货)
由于自己觉着brat蛮好看的,用来给模型的结果展示也不错,决定写个代码转成brat的.ann形式,这里不太方便代码展示了,这里就把整体思路说下:
- 将NER模型输出的words,tags转成结果的词语(比如上面的“姚明”)
- 并将这些词的开始的字和结尾的字所在位置索引记录下来
- 如果涉及换行,需要将索引 += 改行句子的长度
这里用mydata/1.ann来举例,如下图所示

T1 person 0 2 姚明
T2 person 8 10 小明
T3 person 12 14 姚明
T4 like 10 12 喜欢
T5 like 2 4 喜欢
R1 Act-Person Arg1:T1 Arg2:T5
R2 Act-Person Arg1:T2 Arg2:T4
规律:
- 想要转成.ann格式,我们可以看到每一行都是固定的格式,即:
T总序列号\t类别名 该词开始所在索引 该词结束所在索引\t该词 - 如果换行了,比如第二行的“小明”,这里的开始索引 = 第一句长度 + “小”字所在第二句的位置