分布式训练推理Accelerate
分布式训练的加速策略详情可见本人上篇文章《 大语言模型的应用及训练》,一般有三种,分别是数据并行,流水线式并行和张量并行,本文主推使用hugging face的accelerate库来进行模型分布式的训练和推理。
一. torch常用的分布式训练工具
1.1 DataParallel
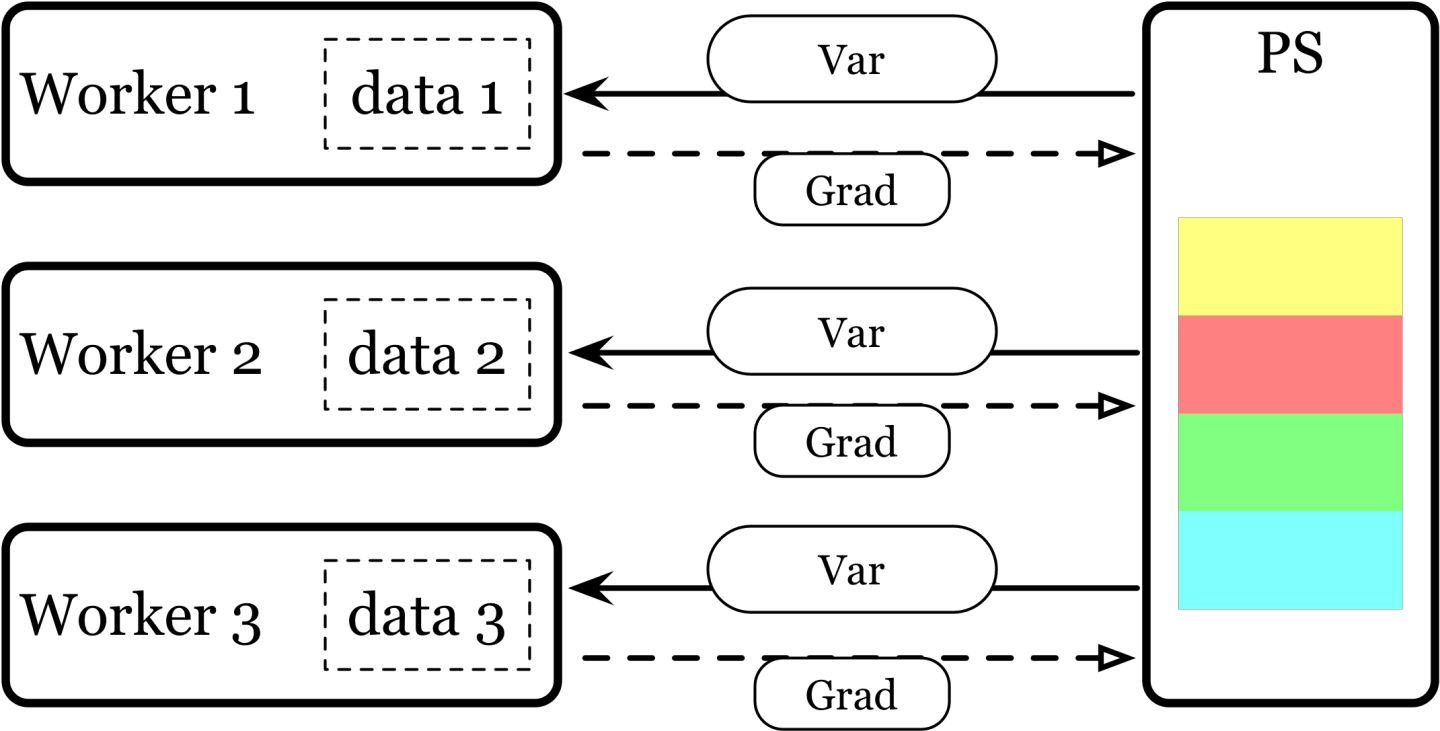
DP(DataParallel):实现数据并行方式的分布式训练,采用的是PS(worker-server)模式,不推荐。
- 单进程多线程
- 只能在单机上使用
- 训练速度慢,且由于是PS模式(存在负载不均衡的问题),随着worker的个数增多,训练速度越慢
1.2 DistributedDataParallel
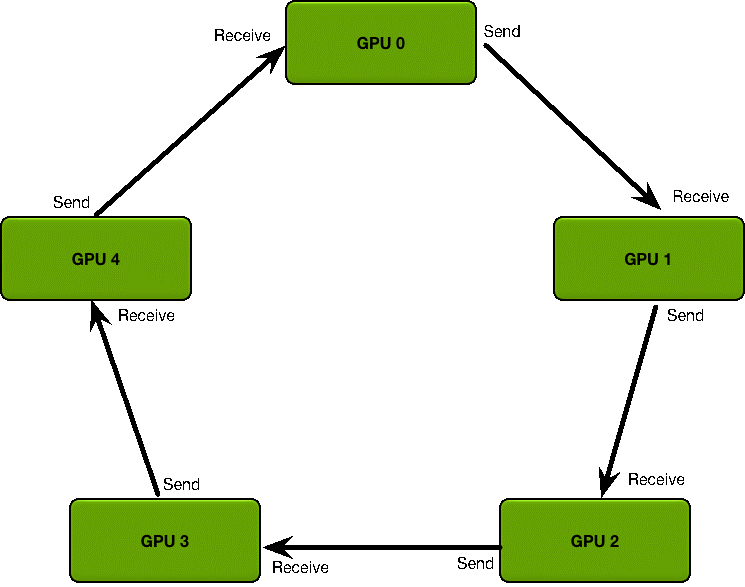
DDP(DistributedDataParallel):实现数据并行方式的分布式训练,采用的是ring-all-reduce模式。它将模型复制到每个 GPU 上 ,同时复制了每个dataloader,并且当 loss.backward() 被调用进行反向传播的时候,所有这些模型副本的梯度将被同步地平均/下降 (reduce)。这确保每个设备在执行优化器步骤后具有相同的权重。
-
多进程
-
支持多机多卡
-
训练速度较DP快,ring-all-reduce模式下,所有worker只和自己相邻的两个worker进行通信
1.3 amp
apex由英伟达开发了一个支持半精度自动训练的pytorch拓展插件。Apex 对混合精度训练的过程进行了封装,从而大幅度降低显存占用,节约运算时间。torch 原生支持的amp,pytorch的版本一定>1.6。不用额外再装apex,所以推荐使用这种方式使用amp。
from torch.cuda.amp import autocast as autocast, GradScaler
# 在训练最开始之前实例化一个GradScaler对象
scaler = GradScaler()
for input, target in tqdm(loader):
# 前向过程(model + loss)开启 autocast
with autocast():
output = model(input)
loss = loss_fn(output, target)
# Scales loss,这是因为半精度的数值范围有限,因此需要用它放大
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
二. Accelerate分布式训练和推理
Accelerate:在无需大幅修改代码的情况下完成并行化。同时还支持DeepSpeed的多种ZeRO策略,简直不要太爽。
-
代码效率高,支持无论是单机单卡还是多机多卡适配同一套代码。
-
允许在单个实例上训练更大的数据集:Accelerate 还可以使
DataLoaders更高效。这是通过自定义采样器实现的,它可以在训练期间自动将部分批次发送到不同的设备,从而允许每个设备只需要储存数据的一部分,而不是一次将数据复制四份存入内存。 -
支持DeepSpeed:无需更改代码,只用配置文件即可对DeepSpeed开箱即用。
2.1 分布式推理
当模型参数大到单张卡放不下时候(哪怕batchsize为1也会报显存不足的情况),这里就需要将大模型中的不同layer放到不同的GPU上,而每个GPU只负责其中一部分训练,当然数据在不同卡上流转的时候,都需要自动将数据放到对应的卡上。
from accelerate import dispatch_model
# device_map设置为自动的最方便了,不用自己设计把模型的layer分配到哪个GPU
model = dispatch_model(model, device_map="auto")
# 打印device_map
print(model.hf_device_map)
print(f'memory_allocated {torch.cuda.memory_allocated()}')
2.2 分布式训练
下面是官方的例子,只需要更新几行代码即可开启分布式训练之旅啦!
-
accelerator = Accelerator()实例化 -
accelerator.prepare把我们的模型、数据、优化器等等都放进accelerate里面,让他帮我们操作 -
accelerator.backward(loss)替换掉常用的loss.backword() -
如果需要梯度裁剪,这里必须使用
accelerator.clip_grad_norm_() -
涉及到模型存储的时候,需要unwrap 下模型,因为在通过 prepare() 方法时,模型可能被 wrap 从而用于分布式训练
import torch
import torch.nn.functional as F
from datasets import load_dataset
+ from accelerate import Accelerator
+ accelerator = Accelerator()
- device = 'cpu'
+ device = accelerator.device
model = torch.nn.Transformer().to(device)
optimizer = torch.optim.Adam(model.parameters())
dataset = load_dataset('my_dataset')
data = torch.utils.data.DataLoader(dataset, shuffle=True)
+ model, optimizer, data = accelerator.prepare(model, optimizer, data)
model.train()
for epoch in range(10):
for source, targets in data:
source = source.to(device)
targets = targets.to(device)
optimizer.zero_grad()
output = model(source)
loss = F.cross_entropy(output, targets)
- loss.backward()
+ accelerator.backward(loss)
optimizer.step()
# 等待所有进程达到一定程度后再执行指令
accelerator.wait_for_everyone()
# 只在主进程中保存模型
if self._accelerator.is_main_process:
+ unwrapped_model = accelerator.unwrap_model(model)
+ accelerator.save(unwrapped_model,model_path)
- torch.save(unwrapped_model.state_dict, "./model/accelerate.pt")
之后,只需要配置下accelerate的config文件,使用accelerate launch --config_file default_config.yaml train.py启动脚本开始训练啦!
三. accelearte使用例子
3.1 单机多卡
下面是以单机多卡(1机器共2卡)的config.yaml例子,这里是我根据accelerate config 生成后的config文件:
compute_environment: LOCAL_MACHINE
distributed_type: MULTI_GPU
downcast_bf16: 'no'
gpu_ids: all
mixed_precision: 'no'
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: false
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
3.2 多机多卡
下面是以多机多卡(2机器共4卡)的config.yaml例子,这里是我根据accelerate config 生成后的config文件:
compute_environment: LOCAL_MACHINE
distributed_type: MULTI_GPU
downcast_bf16: 'no'
gpu_ids: all
machine_rank: 0
main_process_ip: 主机器的ip
main_process_port: 端口号
main_training_function: main
mixed_precision: 'no'
num_machines: 2
num_processes: 4
rdzv_backend: static
same_network: false
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
3.3 DeepSpeed集成在accelerate上的使用
Deepspeed集成了ZeRO的三种方式,在accelerate中,我们可以直接根据配置文件来选择使用:
- Stage 1:将
optimizer states分片到数据并行workers/GPUs上。 - Stage 2:将
optimizer states + gradients分片到数据并行workers/GPUs上。 - Stage 3 :将
optimizer states + gradients + model parameters分片到数据并行workers/GPUs上。 - Optimizer Offload:将
optimizer states + gradients卸载到CPU/Disk,建立在ZERO Stage 2之上。 - Param Offload:将
model parameters卸载到CPU/Disk,建立在ZERO Stage 3之上。
下面是使用stage3的accelerate配置的例子:
compute_environment: LOCAL_MACHINE
deepspeed_config:
deepspeed_multinode_launcher: standard
gradient_accumulation_steps: 4
offload_optimizer_device: none
offload_param_device: none
zero3_init_flag: false
zero3_save_16bit_model: false
zero_stage: 3
distributed_type: DEEPSPEED
downcast_bf16: 'no'
machine_rank: 0
main_process_ip: 主机器的ip
main_process_port: 端口号
main_training_function: main
mixed_precision: 'no'
num_machines: 2
num_processes: 4
rdzv_backend: static
same_network: false
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
在从机器上我们只需要复制这个config文件和所有的代码数据,并把config.yaml中的machine_rank改成1即可。
两台机器同时启动脚本:accelerate launch --config_file default_config.yaml train.py