NLP数据增强
一. 数据增强的意义
无论是文本还是图像领域,想要的到一个泛化性强,鲁棒性高的深度学习模型,往往数据才是至关重要的,毕竟好的数据决定了模型的上线。
我们建模的时候往往会遇到很多数据问题,比如:
- 数据太少了,训练的模型在其他数据集表现很差。
- 数据分布上呈现拖尾现象(部分类别的数据量很少,样本不均衡问题),训练的模型在部份类别(数据量少)的识别上效果很差。
- 数据标签混乱(人工标记存在很大的问题),训练的模型在本身的验证集/测试集上就很差。
针对第三点,我们还可以人工矫正数据。但是对于第1,2点情况,往往需要更多的数据。因此这里才需要进行数据增强。
二. NLP分类任务的数据增强
2.1 EDA文本数据增强
文本分类任务其实是NLP中最常见也是最基础的任务。这里推荐最基础也是醉简单的数据增强——EDA(Easy Data Augmentation)。
其常见的几种数据增强的方式为:
- 同义词替换:在同义词词典中随机替换文本中的N个词(不包含停用词)
- 随机插入:随机抽取一个词,然后在该词的同义词集合中随机选择一个,插入原句子中的随机位置,重复N次(不包含停用词)
- 随机交换:随机在文本中选择2个词,进行位置交换,重复N次。
- 随机删除:随机删除文本中的N个词汇。
2.2 EDA的使用(干货)
这里推荐一个开源的github仓库,很方便我们进行简单的EDA文本数据增强(中文):https://github.com/zhanlaoban/EDA_NLP_for_Chinese
将该仓库clone到本地后,可以直接使用以下命令进行数据增强:
python3 code/augment.py --input=content.txt --output=content_aug.txt --num_aug=3 --alpha=0.05
EDA输入
我们需要使用以上命令的时候,这里需要将自己的数据变换成EDA输入(即上面命令的content.txt)的形式,我这边写了一个df转成输入的txt的python函数
import pandas as pd
def transfer_input_data(df_small,content = 'content',label = 'result',output = 'tag.txt'):
"""将输入数据转成eda输入的形式label+\t+sentence"""
df_small.reset_index(inplace = True)
with open(output,'w',encoding='utf8') as file:
for i in range(len(df_small)):
label_i = df_small.loc[i,label]
doc_i = df_small.loc[i,content]
line = str(label_i) + '\t' + doc_i + '\n'
file.write(line)
print('write completed!')
EDA输出
我这边将EDA输出的txt(即上面命令的content_aug.txt)转成了df,代码如下:
def transfer_argumentedTxt2csv(argument_txt,content = 'content'):
# 将eda生成的增强后的数据转成df
label = []
sentence = []
with open(argument_txt, 'r', encoding='utf8') as file:
lines = file.readlines()
for line in lines:
label_i, sent_i = line.split('\t')
label.append(label_i)
sent_i = sent_i.replace(' ', '')
sent_i = sent_i.replace('\n', '')
sentence.append(sent_i)
df = pd.DataFrame({content:sentence,'result':label})
return df
三. NER任务的数据增强
相较于文本分类任务对于句子进行分类,NER任务是对于句子中每个字/词进行分类。这时候如果还利用EDA简单的数据增强方式增加数据,这些数据极有可能成为噪声导致NER模型脆弱敏感,反而会使得模型效果变差。
3.1 DAGA数据增强
这里推荐一篇来自南洋理工及阿里达摩院的针对于NER模型的数据增强论文——DAGA 其github开源仓库地址:https://github.com/ntunlp/daga
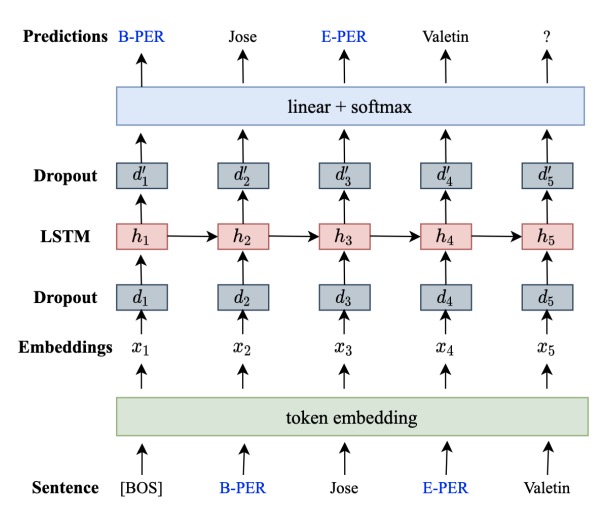
数据处理 整片文章的亮点其实是在数据处理的过程,作者很有意思的将BIOSE标签挪到每个字的前面,当然这里对O标签对应的字不做处理。如下图所示

这样就能将字和标签一同训练,从而很好的拿到标签和字前后呼应的高概率标签和字。
模型
文中采用的是简单的语言模型,如下图所示,将待预测文本输入到词嵌入层后,经过简单的1层LSTM后,后面经过分类输出层输出预测的文本。
3.2 DAGA的使用(干货)
使用的具体步骤:
- clone仓库的代码到本地
- 新建数据存储的目录(输入和输出的dir):
mkdir data & mkdir data/input & mkdir data/output - 新建模型存放的目录:
mkdir model - 新建模型训练的shell脚本:
touch daga_train.sh & chmod +x daga_train.sh - 新建数据生成的shell脚本:
touch daga_generate.sh & chmod +x daga_generate.sh - 使用
daga_train.sh脚本进行训练:./daga_train.sh data/input model - 使用
daga_generate.sh脚本进行数据生成:./daga_generate.sh data/output model 5000这里5000指的是数据生成的个数
daga_train.sh脚本
#!/bin/bash
input_dir_path=$1
model_dir_path=$2
# 1. 标注数据线性化
cd tools
python3 preprocess.py --train_file ../$input_dir_path/train.txt \
--test_file ../$input_dir_path/test.txt --dev_file ../$input_dir_path/val.txt \
--vocab_size 30000
# 2. 训练语言模型
cd ../lstm-lm
python3 train.py --train_file ../tools/train.lin.txt \
--valid_file ../tools/val.lin.txt --model_file ../$model_dir_path/model.pt \
--emb_dim 300 --rnn_size 512 --gpuid 0 --epochs 300
daga_generate.sh脚本
#!/bin/bash
output_dir_path=$1
model_dir_path=$2
gen_sentence_num=$3
# 1. 数据生成
cd lstm-lm
python3 generate.py --model_file ../$model_dir_path/model.pt \
--out_file ../$output_dir_path/out.txt --num_sentences $gen_sentence_num \
--temperature 1.0 --seed 3435 --max_sent_length 128 --gpuid 0
# 2. 数据还原
cd ../tools
python3 line2cols.py --inp_file ../$output_dir_path/out.txt \
--out_file ../$output_dir_path/augment.txt
遇到的问题
- torchtext的版本问题,导致报错
module 'torchtext.data' has no attribute XXX。这里需要将本地的daga代码中所有的torchtext.data改成torchtext.legacy.data即可。 - 模型训练的问题,这里由于默认的是仅有30轮的训练,往往还处理模型欠拟合的时候就训练结束了,导致生成的数据很不理想,因此我们需要加入
--epochs,这里我已经在daga_train.sh脚本中改成了300轮,这里不用担心训练轮数过大导致模型过拟合,因为在训练代码中已经加入了early stop会自动停止训练的。