Selenium和webscraper爬虫
一. Selenium爬虫
1. 安装
Selenium 本身是一个自动化测试的工具,模拟人为在浏览器上进行操作,比如点击和下拉等等。
安装的环境:
- python环境
- pip安装Selenium包:
pip install selenium - chrome浏览器驱动:去官网下载自己电脑已安装的浏览器所在的版本驱动
我这边的chrome驱动装的是mac版本的,这里需要将其路径放到mac的环境变量中,下载后放到了/usr/local/chromedriver,
vim ~/.profile
export PATH="$PATH:/usr/local/chromedriver"
source ~/.profile
可以在控制台打chromedriver测试是否ok。
2. 使用
这里的例子是的主要任务是:将给的头条url所在的公众号遍历其30条的文章标题和链接。
所以我们需要拆解为2步:
- 打开给定的url,并点击头条的公众号。
- 另开一个页面,找到公众号下前30条文章的标题和链接(这里需要下拉才能看到后面的文章)。
第一步:实例一个浏览器驱动,并找到公众号的XPath(这里推荐一个测试XPath的浏览器插件XPath Helper)
driver = webdriver.Chrome()
driver.get(url)
time.sleep(2)
try:
name = driver.find_element(By.XPATH,".//div[@class='article-meta']/span[@class='name']/a").get_attribute('href')
except:
driver.quit()
driver.find_element(By.XPATH,".//div[@class='article-meta']/span[@class='name']/a").click()
由于点击了公众号后会出现一个新的页面,这里最好指定下现在的driver是归属于哪个页面的,不然写的xpath就会找不到元素。
list_windows = driver.window_handles
print(list_windows)
driver.close()
driver.switch_to.window(list_windows[1]) #list_windows 存储了上一步中获取的窗口
time.sleep(2) # 防止页面还未加载完全
第二步:找到所有的页面的文章(这里需要下拉才可以获取)
data = []
titles = set()
last_position = driver.execute_script("return window.pageYOffset;") # 执行下拉操作
scrolling = True
count = 0
while scrolling:
conti_type = True
page_articles = driver.find_elements(By.XPATH, ".//div[@class='profile-article-card-wrapper']")
for art in page_articles[-15:]:
art_url = art.find_element(By.XPATH, ".//div[@class='feed-card-article-l']/a").get_attribute('href')
art_title = art.find_element(By.XPATH, ".//div[@class='feed-card-article-l']/a").text
count += 1
if art_title:
if art_title not in titles:
titles.add(art_title)
data.append((art_url,art_title))
if count > 30:
conti_type = False
scrolling = False
scroll_attempt = 0
while conti_type:
# check scroll position
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
time.sleep(0.5)
curr_position = driver.execute_script("return window.pageYOffset;")
if last_position == curr_position:
scroll_attempt += 1
# end of scroll region
if scroll_attempt >= 50:
scrolling = False
break
time.sleep(1)
else:
time.sleep(0.5) # attempt another scroll
else:
last_position = curr_position
break
二. Web Scraper浏览器插件爬取
用过selenium之后,觉得如果能不写代码就能够实现上面的代码功能多好啊,确实有这样一个chrome插件可以进行替代——Web Scraper
2.1 安装
直接打开chrome应用商店进行搜索Web Scraper,下载安装插件即可。
在chrome中打开一个页面,点击右键,选择检查,即可看到web scraper了。

2.2 使用
还是利用上面的例子,这里用Web Scraper来不写代码进行爬取。
-
新建一个sitemap,选择
create new sitemap, 填写名称和url,如下图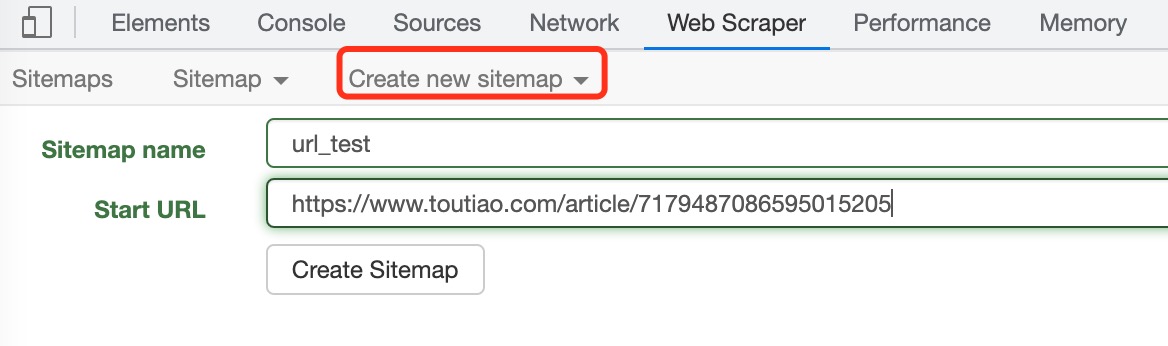
-
选择初始的选择器,这里选择的是公众号名字。注意这里是需要点击“公众号”,因此选择link。
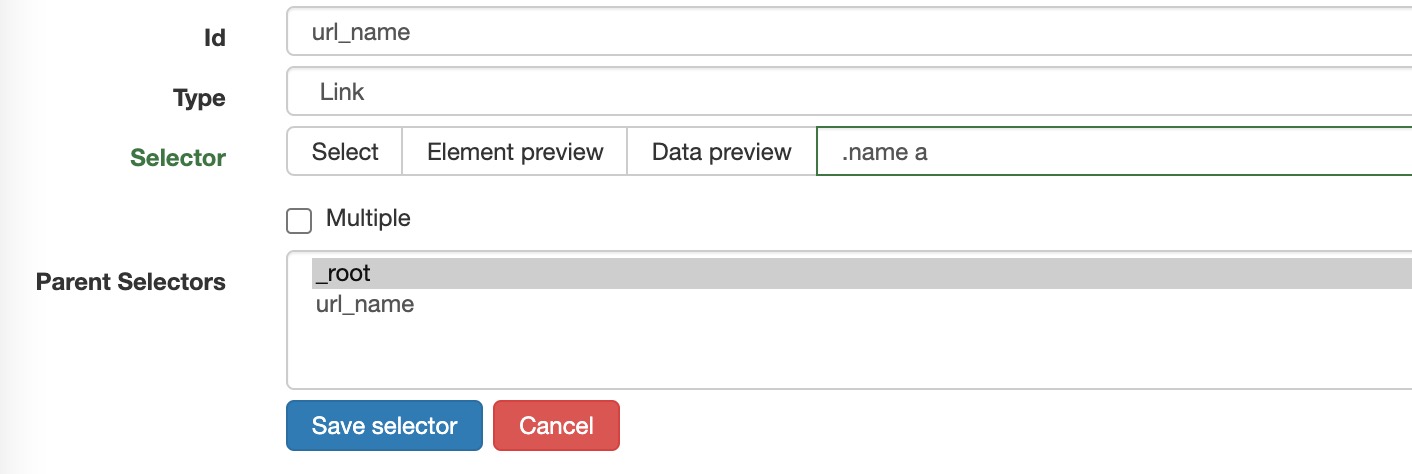
-
在上面选择的选择器中点进去后,新建一个选择器,这里是需要下拉动作,因此选择element scroll down。
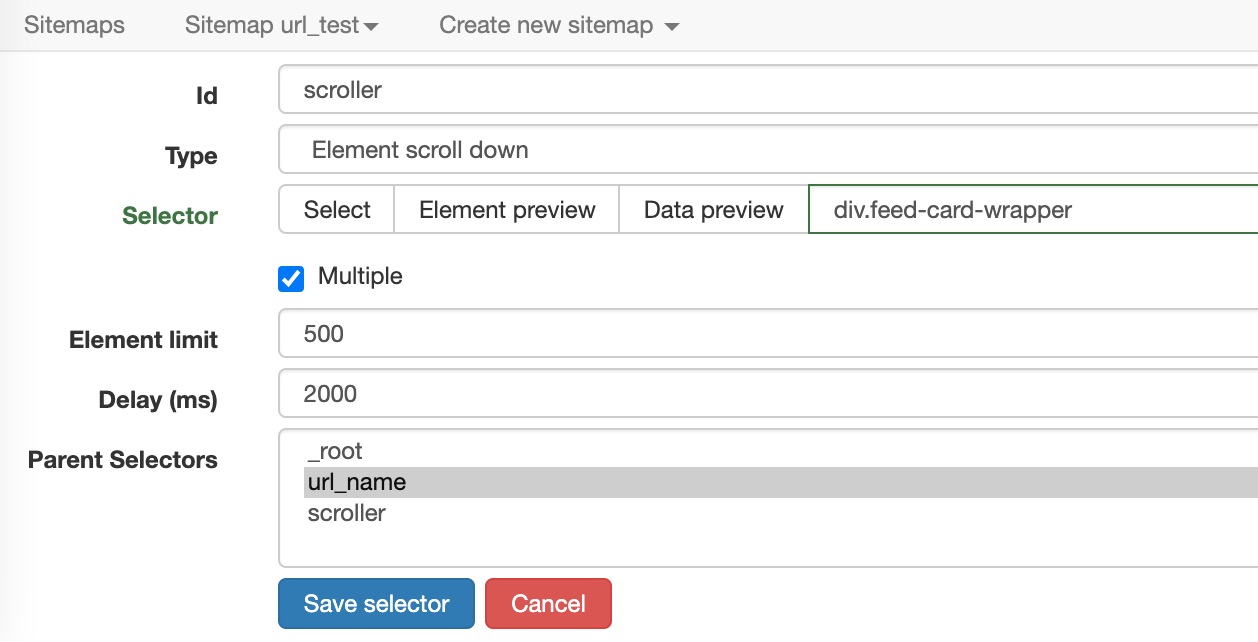
-
点击scroller,新建一个选择器,用以保存文章标题。
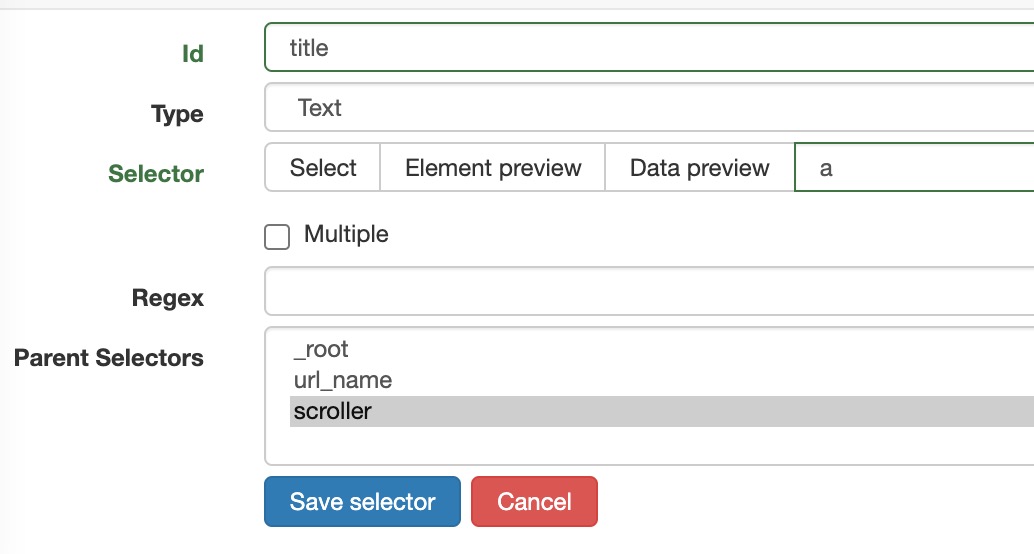
-
同时在scroller下新建一个选择器,用以保存文章链接。
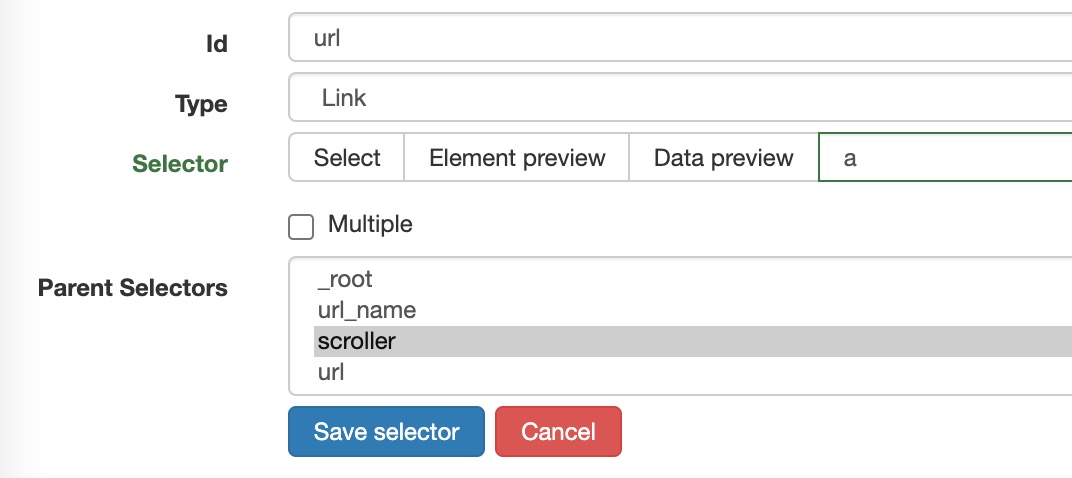
-
我们可以通过查看graph的形式来查看整个workflow(点击
sitemap下的Selector graph)。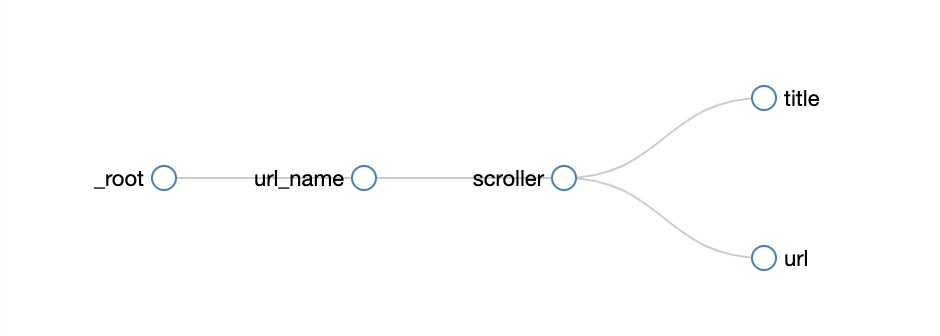
-
至此,配置部分就全部完成了,现在只需要跑起来就行,点击
sitemap下的Scrape即可。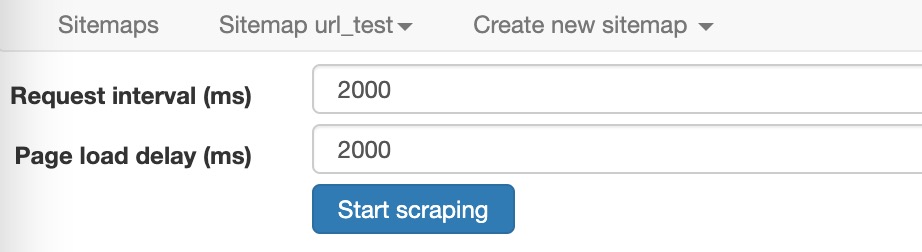
三. AutoScraper推荐
这里推荐一个不需要xpath来选择元素的自动爬取器,很有意思。
git地址:https://github.com/alirezamika/autoscraper
这里其实类似于构建一个爬取器的模型,先选择一个链接中的几个独有的元素,然后放到autoscraper里面,让其知道需要爬取的位置在哪。
from autoscraper import AutoScraper
url = 'https://stackoverflow.com/questions/2081586/web-scraping-with-python'
# We can add one or multiple candidates here.
# You can also put urls here to retrieve urls.
wanted_list = ["What are metaclasses in Python?"]
scraper = AutoScraper()
result = scraper.build(url, wanted_list)
print(result)
然后再给予一个相同的链接,让其自动找到我们需要找的元素信息。
scraper.get_result_similar('https://stackoverflow.com/questions/606191/convert-bytes-to-a-string')