pytorch使用YOLOv5训练数据
一. 需要下载的资源
- Fork 下官方的开源项目:https://github.com/ultralytics/yolov5
- git clone 下Fork之后的项目到自己本地仓库中。
- 采用的训练集(简单的,仅有一个类):源自Kaggle的小麦数据集
- 如果有gpu的话,最好安装cuda进行训练加速,这里可以参考本人的另一篇文章:Windows10环境下搭建CUDA10.1和pytorch1.6
二 . 构建属于自己的目标检测模型
2.1 在官网的开源yolo5项目的基础上进行构建
- git 克隆到本地仓库:
git clone https://github.com/xx/yolov5.git - 进入项目中,并安装需要的第三方依赖:
pip install -r requirements.txt - 新建一个原始数据的目录::
mkdir ori_data,将下载好的小麦数据集解压后放到项目。 - 创建输出一个文件输出目录:
mkdir wheat_data,并在此目录下新建以下目录,如下图所示├─images │ ├─train │ └─val └─labels ├─train └─val - 构建数据集,新建一个
munge_data.py文件
import os
import pandas as pd
import numpy as np
import ast
from sklearn.model_selection import train_test_split
from tqdm import tqdm
import shutil
DATA_PATH = 'ori_data'
OUTPUT_PATH = 'wheat_data'
def process_data(data,data_type = 'train'):
for _,row in tqdm(data.iterrows(),total=len(data)):
image_name = row['image_id']
bounding_boxes = row['bbox']
yolo_data = []
for bbox in bounding_boxes:
x = bbox[0]
y = bbox[1]
w = bbox[2]
h = bbox[3]
x_center = x+w/2
y_center = y+h/2
# 这里需要将图像数据归一化处理(yolo需要的输入为归一化后的数据,且为浮点数)
x_center /= 1024.0
y_center /= 1024.0
w /= 1024.0
h /= 1024.0
yolo_data.append([0,x_center,y_center,w,h])
yolo_data = np.array(yolo_data)
# 保存bbox的图片信息
np.savetxt(
os.path.join(OUTPUT_PATH,f'labels/{data_type}/{image_name}.txt'),
yolo_data,
fmt=['%d','%f','%f','%f','%f']
)
# 将目标图片文件保存到指定文件中
shutil.copyfile(
os.path.join(DATA_PATH,f'train/{image_name}.jpg'),
os.path.join(OUTPUT_PATH,f'images/{data_type}/{image_name}.jpg'),
)
if __name__ == "__main__":
df = pd.read_csv(os.path.join(DATA_PATH,'train.csv'))
# 将string of list 转成list数据
df.bbox = df.bbox.apply(ast.literal_eval)
# 利用groupby 将同一个image_id的数据进行聚合,方式为list进行,并且用reset_index直接转变成dataframe
df = df.groupby(['image_id'])['bbox'].apply(list).reset_index(name = 'bbox')
# 划分数据集
df_train,df_val = train_test_split(df,test_size=0.2,random_state=42,shuffle=True)
# 重设 index (这里数据被打乱,index改变混乱)
df_train = df_train.reset_index(drop=True)
df_val = df_val.reset_index(drop=True)
process_data(df_train,data_type='train')
process_data(df_val,data_type='val')
-
运行构建数据的py文件:
python munge_data.py -
这里可以看到在输出结果目录中,放入了需要的整理后的数据集
-
新建一个
wheat.yamlyaml文件,指定模型训练时候的输入及其类别(注意这里冒号后面要加空格,yamal格式问题)
train: wheat_data/images/train // 指定训练目录
val: wheat_data/images/val // 指定验证目录
nc: 1 // 指定类别
names: ["wheat"] // 指定类别名字
- 进行模型训练:
python3 train.py --img 1024 --batch 8 --epoch 100 --data wheat.yaml --cfg .\models\yolov5s.yaml --name wm
- 这里可能会报错(Dataloader中设置了多进程导致的),报错信息如下所示:
File "C:\soft\python3.7.9\lib\multiprocessing\reduction.py", line 60, in dump
ForkingPickler(file, protocol).dump(obj) BrokenPipeError: [Errno 32] Broken pipe
这里可以参考文章:https://github.com/pytorch/pytorch/issues/2341。解决方案:将utils\datasets.py文件中num_workers改成0即可(代码第68行)。训练完成后如下图:

- 可以查看本地tensorboard训练过程:
tensorboard --logdir=runs,如果这里出现问题,可以换成一下命令:python -m tensorboard.main --logdir logs
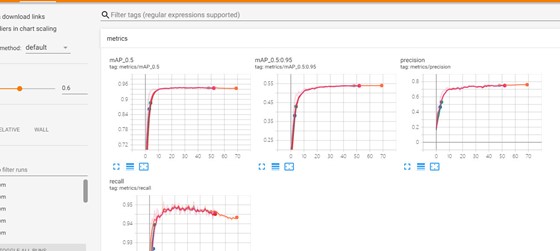
- 这里还可以使用coco数据集的预训练模型进行训练,可能效果会更好
python3 train.py --img 1024 --batch 8 --epoch 100 --data wheat.yaml --cfg .\models\yolov5s.yaml --name wm --weights
-
将训练好的模型放到当前文件夹下:
cp runs/exp0_wm/weights/best.pt . -
选择测试图片的文件夹进行生成测试:
python detect.py --source ./test_data --weights best.pt,这里可以看到新生成一个文件夹inference/output中就是测试后标记bbox后的图片。