GCN在多标签分类中的应用
一. Torch的图神经网络库pyG
torch_geometric 官方文档:https://pytorch-geometric.readthedocs.io/en/latest/index.html
1.1 安装及使用
这里参考官网的安装过程。
-
确定自己安装的pytorch版本:
pip list进行查看,例如本人的torch版本为1.6.0+cu101(这里的cu101是指cuda10.1) -
安装相关的第三方包,这里注意要匹配上面的torch版本,因此:
${TORCH} = 1.6.0,${CUDA} = cu101pip install --no-index torch-scatter -f https://pytorch-geometric.com/whl/torch-${TORCH}+${CUDA}.html pip install --no-index torch-sparse -f https://pytorch-geometric.com/whl/torch-${TORCH}+${CUDA}.html pip install --no-index torch-cluster -f https://pytorch-geometric.com/whl/torch-${TORCH}+${CUDA}.html pip install --no-index torch-spline-conv -f https://pytorch-geometric.com/whl/torch-${TORCH}+${CUDA}.html pip install torch-geometric -
安装完成之后,测试下
import torch_geometric导包没有报错说明安装完成了。
1.2 图数据导入
torch_geometric.data这个模块包含了一个叫Data的类,而这个类可以很方便的构建属于自己的数据集。data实例有以下属性:
x:节点的特征矩阵,shape = [节点个数,节点的特征数]。edge_index:这里可以理解为图的邻接矩阵,但是要注意这里要将邻接矩阵转换成COO格式,shape = [2, 边的数量],type = torch.long。edge_attr:边的特征矩阵,shape = [边的个数,边的特征数]y:标签,如果任务是图分类,shape = [1, 图的标签数];如果是节点分类,shape = [节点个数,节点的标签数]。(这里注意一哈:在torch中如果是多分类任务,不用转成onehot形式哦,因此标签数为1)is_directed():是否是有向图
(1) 下面是edge_index的具体从邻接矩阵生成COO模式的代码。
from scipy.sparse import coo_matrix # 转化成COO格式
coo_A = coo_matrix(adj_arr)
edge_index = [coo_A.row, coo_A.col]
(2) 构建自己的数据集,只需要用list来封装这些Data即可。具体代码如下:
dataset = [Data(x,edge_index,y) for _ in range(10)]
1.3 图数据的转换及展示
我们可以利用networkx来对Data这个图进行展示和转换成networkx的图结构。
from torch_geometric.utils.convert import to_networkx
import networkx as nx
def draw(Data):
G = to_networkx(Data)
nx.draw(G)
nx.write_gexf(G, "test.gexf")
plt.savefig("path.png")
plt.show()
同时,还可以将gexf格式的图数据文件经过Gephi这个开源的图数据展示软件来进行节点的渲染。
二. 图卷积网络GCN在多标签分类中的应用
论文参考:Semi-Supervised Classification with Graph Convolutional Networks
2.1 GCN在模型应用上的优缺点。
本次探究的是图卷积网络在图分类(多标签)上的应用,因此不涉及到节点的分类任务。
GCN的优点:可以捕捉图的全局信息,很好的表征节点的特征,边的特征。
GCN的缺点:若是新增节点,整个图发生变化, 那么GCN的结构就会发生变化。因此对于节点不固定的图结构来说,不适用。
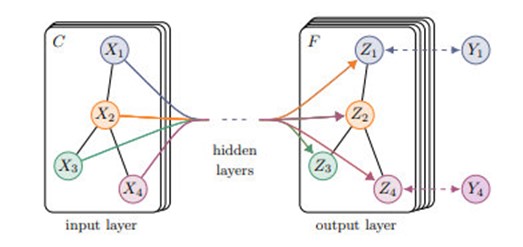
GCN的主要作用:抽取图中节点的拓扑信息(节点的邻接信息)。这里学到的是每个节点的一个唯一确定的embedding。如下图所示,多层的GCN抽取的是每个节点的唯一确定的embedding。
GCN的特性:
- 局部参数共享,算子是适用于每个节点(圆圈代表算子),处处共享。
- 感受域正比于层数,最开始的时候,每个节点包含了直接邻居的信息,再计算第二层时就能把邻居的邻居的信息包含进来,这样参与运算的信息就更多更充分。层数越多,感受域就更广,参与运算的信息就更多。
2.2 GCN在图分类的模型搭建
图分类任务下的模型搭建过程如下:
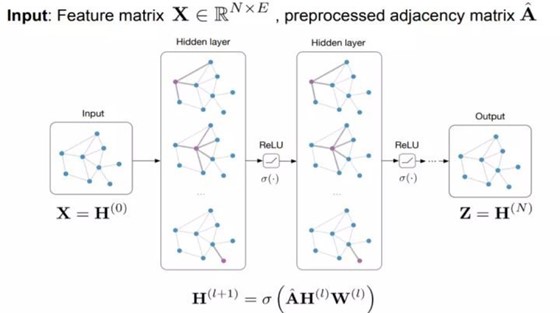
因此,利用pytorch_geometric来搭建图分类任务(多标签)的模型。这里代码中引入了两次图卷积和池化。在输入的数据中,除了包含节点的特征,还包含了边的特征。
import torch
import torch.nn.functional as F
from torch_geometric.nn import GraphConv, TopKPooling
from torch_geometric.nn import global_mean_pool as gap
from torch_geometric.nn import global_max_pool as gmp
class Net(torch.nn.Module):
def __init__(self, num_features,multi_label):
super(Net, self).__init__()
self.conv1 = GraphConv(num_features, 8)
# self.conv1.weight.data.normal_()
self.pool1 = TopKPooling(8, ratio=0.5)
self.conv2 = GraphConv(8, 8)
self.pool2 = TopKPooling(8, ratio=0.5)
self.lin1 = torch.nn.Linear(16, 64)
self.lin2 = torch.nn.Linear(64, 128)
self.lin3 = torch.nn.Linear(128, multi_label)
def forward(self, data):
x, edge_index,edge_attr, batch = data.x, data.edge_index, data.edge_attr,data.batch
x = F.relu(self.conv1(x,edge_index,edge_attr))
x, edge_index, edge_attr, batch, _, _ = self.pool1(x, edge_index, edge_attr, batch)
x1 = torch.cat([gmp(x, batch), gap(x, batch)], dim=1)
x = F.relu(self.conv2(x, edge_index,edge_attr))
x, edge_index, edge_attr, batch, _, _ = self.pool2(x, edge_index, edge_attr, batch)
x2 = torch.cat([gmp(x, batch), gap(x, batch)], dim=1)
x = x1 + x2
x = F.relu(self.lin1(x))
x = F.dropout(x, p=0.3, training=self.training)
x = F.relu(self.lin2(x))
x = F.dropout(x, p=0.3, training=self.training)
x = torch.sigmoid(self.lin3(x))
return x
2.3 多标签(Multi-Label)分类任务
在多标签分类任务中:
- 输入的y:shape = [batch_size, multi-label的个数],其中multi-label的形式都是[0,1,0,0,1….],即每个类别之间都互不影响,且结果只有0和1。这里在
torch_geometric.data.y的shape = [1,multi-label的个数]。 - 分类模型的最后一层激活函数:
torch.sigmoid()函数(即二分类常用的激活函数),这里对于多标签分类任务同样适用。 - 损失函数的定义:
torch.nn.BCELoss() - 准确率的定义:在训练的时候,一般除了看训练集和验证集的loss以外,acc其实也可以当作模型好坏的指标。但是对于多标签分类而言,这里和一般的多分类,二分类任务定义的准确率不太一样。个人的理解(可能不对蛤):对于一个样本(多标签)而言,有且仅有每个标签都预测对了,这个样本才能算预测正确了,因此,定义了以下acc。
pred = torch.where(pred>acc_thread ,torch.ones_like(pred),torch.zeros_like(pred))
acc = 0
for i in range(pred.shape[0]):
if pred[i].int().equal(data.y[i]):
acc +=1
epoch_accuracy += acc