目标检测(one stage)-YOLOv1
一. 目标检测算法的分类及历史
1.1 目标检测算法的分类
目标检测算法主要分为2大类:
- one-stage(one-shot object detectors) :直接预测目标的bounding box及其类别。特点是一步到位,速度很快。比如:YOLO,SSD等系列模型。
- two-stage:需要先使用启发式方法(selective search)或者CNN网络(RPN)产生Region Proposal,然后再在Region Proposal上做分类与回归。特点是:慢,但是准确率高。比如:RCNN系列模型。
由于在工业应用中,往往对模型预测速度有要求,而two-stage目标检测模型由于先天的不足,因此本文仅考虑one-stage目标检测模型。
1.2 目标检测发展流程
目标检测(one-stage)的总体发展流程:
- 2015.06 — YOLOv1:第一个one-stage目标检测器。
- 2015.12 — SSD:结合anchor box和多尺度特征的one-stage目标检测器。
- 2016.12 — YOLOv2:YOLO的第二版。
- 2016.12 — FPN:特征金字塔(结合不同尺寸的特征图像)
- 2017.01 — DSSD:SSD结合FPN。
- 2017.08 — RetinaNet:Focal Loss解决正负样本不均衡
- 2018.04 — YOLOv3:YOLO的第三版。
- 2018.07 — CBAM:Attention机制的目标检测。
- 2019.11 — EfficientDet:Google提出的目标检测器。
- 2020.04 — YOLOv4:YOLO的第四版。
- 2020.06 — YOLOv5:YOLO第五版。
二. YOLO
当我最初学习图像分类的时候,就一直疑惑:如果我利用卷积层抽取目标特征后直接把分类任务做成回归任务(包含目标的位置和类别信息)可以作为目标检测器么?答案来了——YOLO(You Look Only Once)。
2.1 模型结构
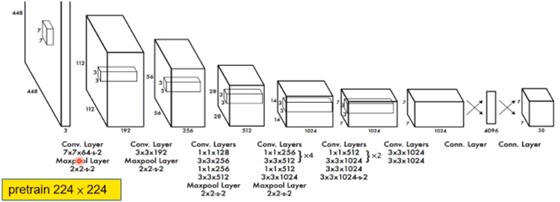
YOLO模型的结构如上所示:
-
输入为一个448*448的一个图片输入。
- 一共是经过24层的卷积层抽取特征,使用relu作为每一层的激活函数。
- 最后通过全连接层,且output形式为[7,7,30]的输出。
模型输出的理解:
- 将448 * 448的图像分为7 * 7的grid(网格),每个grid都会进行判断:是否为前景,且会构建2个boundingbox来框出物体。因此,一共是有7 * 7 * 2个框。而每个grid都会输出x,y,w,h,c;这里的confidence的计算就是前景目标的概率 * iou的值。
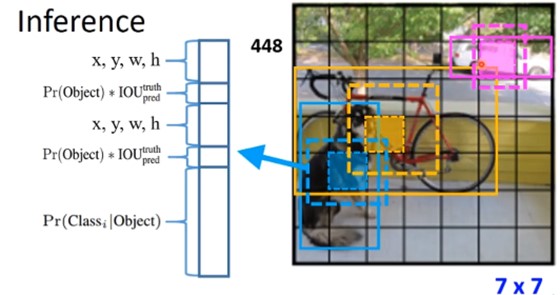
- 除了boundingbox的计算外,当然还需要输出目标是哪个类别,即输出检测到的目标是某个类别的概率。这样就可以计算每个grid属于某个类别下的iou情况了。
- 最后利用NMS(非极大值抑制:顾名思义就是不是最大的置信度就不要了)找到每个目标的最合适的框。具体NMS的算法步骤如下:
- (1)首先拿到的是YOLO模型输出的结果,即7 * 7 * 2个框,每个框都是由5个元素(x,y,w,h,c)。这里需要知道一张图片中有多少个目标且目标confidence最高的结果。
- (2)通过计算两两框之间的IOU(交并比),用来划分一张图片中有多少个目标(如果IOU>0说明属于同一目标下的框)。
- (3)对同一目标下的所有框的confidence进行排序,找到最大的的confidence对应的框。
2.2 模型训练
这里主要讲述模型训练过程中loss的定义过程。
2.2.1 Location Loss
定义如下所示:
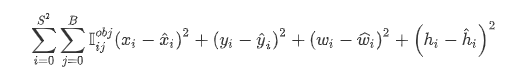
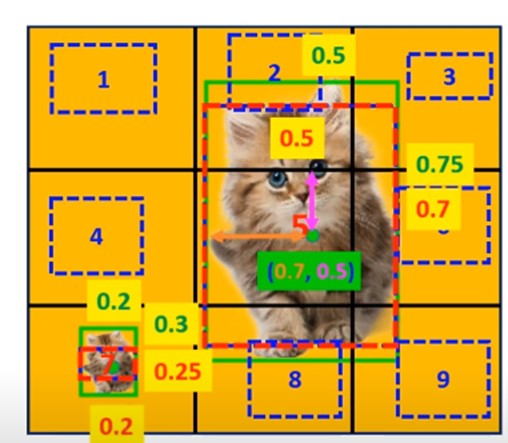
如上所示,假定是将图片划分为3 * 3个grid,每个grid有且仅有一个预测框,由于只计算和前景目标匹配的框,因此只会计算grid5和grid7的location loss。
-
grid5的loss:
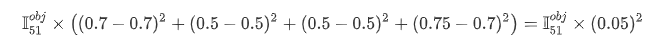
-
grid7的loss:
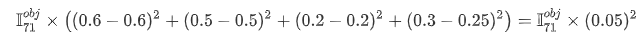
但是这里看大大猫和小猫的loss竟然是一样的,大猫的loss应该明显要小一些,而小猫的loss明显要大一些。因此这种loss的计算还需要提升。这里就将w,h的分别先进行开根号处理。
- grid5的loss:
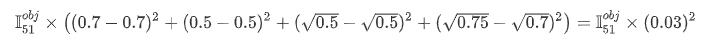
- grid7的loss:
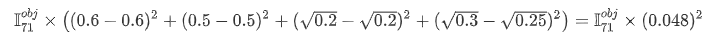
2.2.2 Object Loss
定义如下:
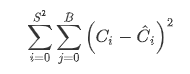
那么上图的每个grid的confidence的值如下:
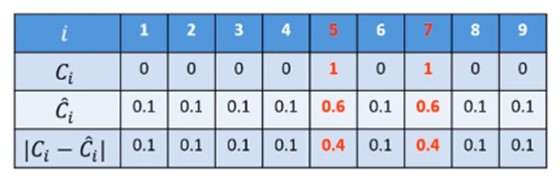
object loss的值为:
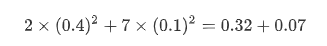
但是这个是只划分了3 * 3个grid的,那么如果是原论文中的7 * 7的情况下呢,此时的object loss的值为:
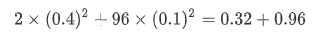
我们可以看到,0.96这个检测的背景的loss就过大了,那么在反向传播的过程中,梯度的变化很大程度就着重在背景的部分,以至于学习前景的能力较差。
因此,重新定义object loss(其实就是在背景loss引入一个系数,比如0.5):
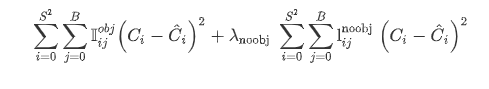
2.2.3 classification loss
定义如下:
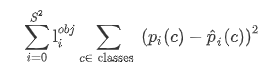
2.4 YOLO存在问题
2.4.1 同一个grid却是多个目标的中心点

如上图所示,人和车的中心点基本都落在中心的grid中,对于yolo而言,就无法分辨到底是人还是车?一个grid下只能预测1个目标。
2.4.2 同一个grid中存在多个小目标

如上图所示,同一个grid下有多个鸟(小目标),而对于yolo而言,一个grid下只能预测1个目标。